MultiLexScaled
A python module for sentiment analysis
By A. Maurits van der Veen in code python sentiment analysis
December 10, 2021
Lexicon-based sentiment analysis, using multiple lexica and scaled against representative text corpora.
Sentiment analysis — the study of the positive or negative valence of texts — has wide-ranging applications across the social sciences. Automated approaches make it possible to code near unlimited quantities of texts with full replicability and high accuracy. Compared to machine-learning approaches, lexicon-based methods provide generalizability while sacrificing little in performance and gaining the ability to identify gradations in sentiment as well as cross-domain comparability.
In conjunction with the book, we introduced a method, MultiLexScaled, which averages valences across a number of widely-used general-purpose lexica. The paper presenting the method has been published at PLOS One, with the title “The advantages of lexicon-based sentiment analysis in an age of machine learning.” In it, we validate the method against several benchmark datasets across a range of different domains and languages.
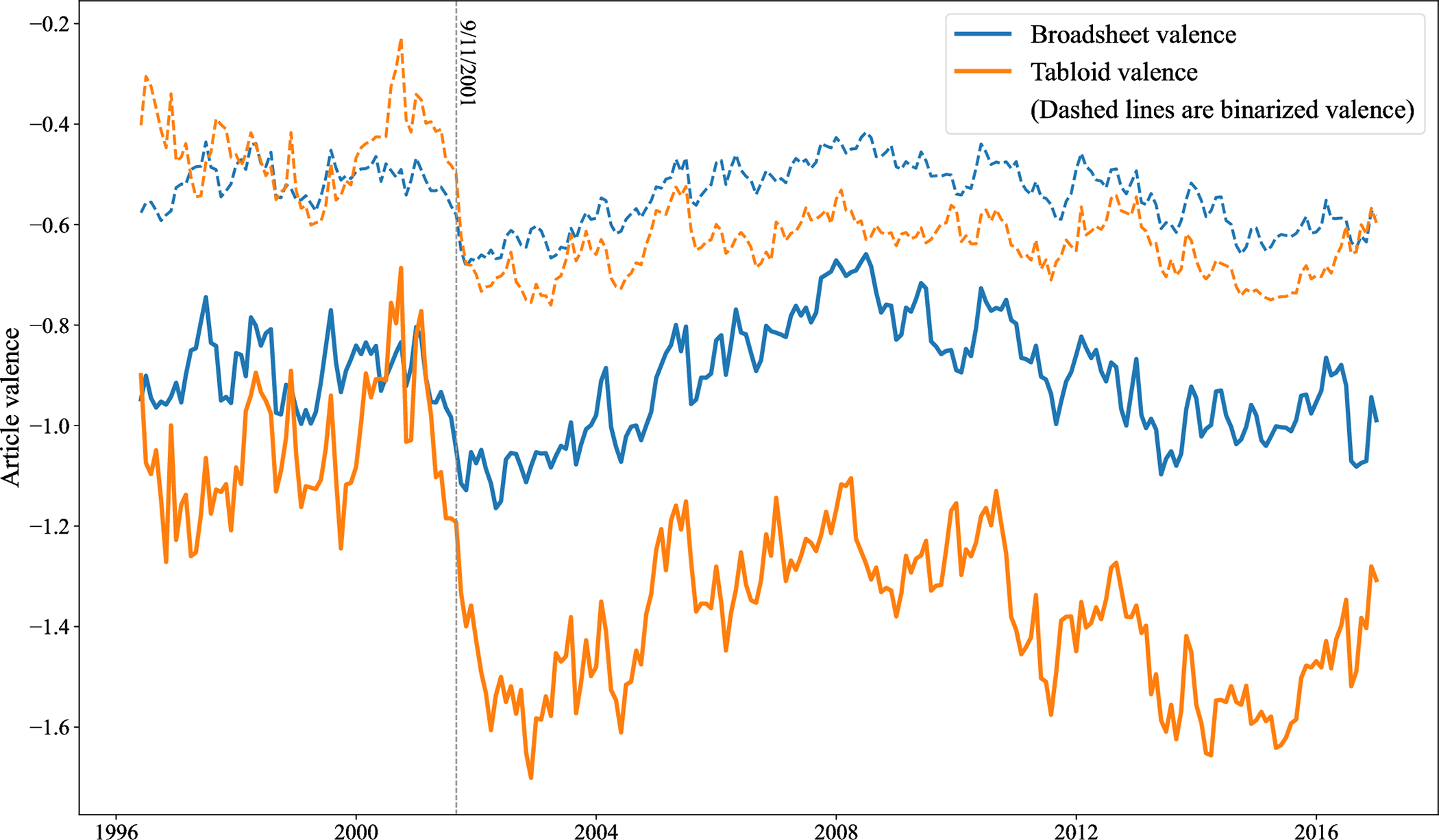
We further illustrate the value of identifying sentiment in a fine-grained manner by examining coverage of Muslims in the British press, showing among others that tabloids and broadsheet papers diverged noticeably after 9/11, with tabloids becoming decidedly more negative about Muslims while the tone of broadsheet articles about Muslims remained relatively unchanged.
- Posted on:
- December 10, 2021
- Length:
- 1 minute read, 194 words
- Categories:
- code python sentiment analysis
- Tags:
- hugo-site